How Search Engines Work: Crawling, Indexing, and Ranking
Google's original search engine prototype, called Backrub, ran on a handful of servers in Larry Page's Stanford dorm room in 1996. Its defining contribution wasn't speed or a sleek interface.
How Search Engines Work: Crawling, Indexing, and Ranking — Traced from One Algorithm to the Modern Pipeline
Google's original search engine prototype, called Backrub, ran on a handful of servers in Larry Page's Stanford dorm room in 1996. Its defining contribution wasn't speed or a sleek interface. It was a single algorithmic idea: the importance of a webpage could be estimated by counting and weighting the links pointing to it. That idea, formalized as PageRank in a 1998 paper by Page and Sergey Brin, became the backbone of a company now processing hundreds of billions of queries against hundreds of billions of webpages. But PageRank only handled one piece of the puzzle: ranking. Two other stages had to work first. The page had to be found, and then it had to be understood. Those three stages—crawling, indexing, and ranking—remain the core pipeline that every search engine operates today, even as the details have grown enormously more complex. Tracing how that pipeline evolved from Backrub's original design reveals what actually happens to a URL between the moment it's published and the moment it shows up (or doesn't) in search results.
Backrub's Original Crawl and the Link Graph It Built
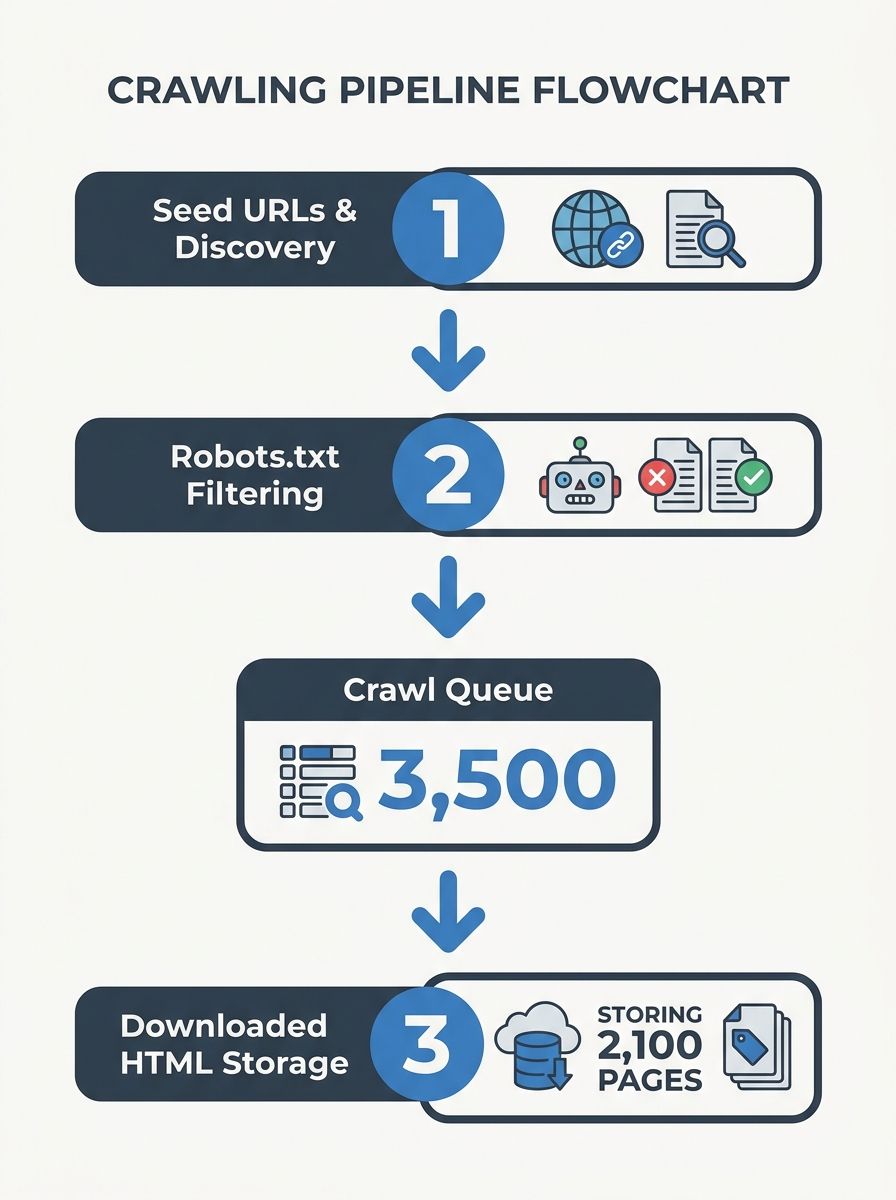
Before Page and Brin could rank anything, they needed a copy of the web. Backrub's crawler started with a set of seed URLs and followed every hyperlink it found, downloading pages and storing them for analysis. This is still how web crawlers work. As Cloudflare's documentation describes it, crawlers fetch the pages at seed URLs first, discover hyperlinks on those pages, and add the new URLs to a queue. The process repeats recursively, building an ever-expanding map of the web.
Googlebot, the modern descendant of Backrub's crawler, does this at scale. It manages a crawl queue of billions of URLs, prioritizes them by signals like how frequently a page changes and how many other pages link to it, and distributes the work across thousands of machines. If you're new to thinking about what organic search actually means, this is the mechanical foundation underneath it: your page can only appear in organic results if a crawler has found it and fetched it first.
There are a few ways a URL enters the crawl queue. Googlebot might discover it by following a link from another page it already knows about. You can also submit an XML sitemap through Google Search Console, which directly tells Google about pages you want crawled. And you can structure your robots.txt file to tell Googlebot which sections of your site it should or shouldn't access. Google's documentation on crawling and indexing covers these controls in detail.
A critical concept here is crawl budget—the number of pages Googlebot will fetch from your site in a given period. Server response time matters. Research suggests a 100ms improvement in server speed can increase crawling activity by roughly 15%. If your server regularly throws 5xx errors or responds slowly, Googlebot backs off. It doesn't wait around. Pages that never get crawled never get indexed, and pages that never get indexed can't rank. The pipeline is sequential and unforgiving.
From Raw HTML to a Searchable Index
Crawling a page and understanding a page are different things. Once Googlebot fetches a URL, the content has to be processed and stored in a way that makes it searchable. This is indexing.
In Backrub's era, indexing was relatively straightforward: parse the HTML, extract the text, note which words appeared and where on the page, and store that information in an inverted index—essentially a giant lookup table that maps every word to every page containing it. If someone searched for "Stanford computer science," the engine could instantly find all pages in its index containing those terms.
Modern indexing is far more involved. Google renders JavaScript, processes metadata, evaluates structured data markup, and analyzes the semantic relationships between entities on a page. The Elastic team describes indexing as organizing data within a given schema or structure, and that definition still holds, but the schema itself has become extraordinarily rich. Google doesn't just know that your page contains the word "mortgage." It understands that the page discusses 30-year fixed-rate mortgages in the context of first-time homebuyers in a specific geographic market.
Canonical URLs play a big role in this stage. If Google discovers three URLs that all serve the same content (say, example.com/shoes, example.com/shoes?color=red, and example.com/shoes?ref=email), it needs to pick one canonical version to index. You can specify this with a rel="canonical" tag. If you don't, Google picks for you, and it doesn't always choose the one you'd prefer.
Here's a statistic that should sharpen your attention: according to Ahrefs data, 96.55% of all indexed pages receive zero organic traffic. Being indexed is a necessary condition for ranking, but it is nowhere close to sufficient. Your page can sit in Google's index indefinitely without ever appearing in a single search result.
Five Hundred Signals, One Results Page
Ranking is where things get competitive. Google's systems sort through hundreds of billions of webpages and other content to present results it considers most relevant, most useful, in a fraction of a second. The original mechanism for this was PageRank: each link to a page counted as a vote, and votes from pages that themselves had many votes counted for more. It was elegant, and it worked well enough to crush every competing search engine in the early 2000s.
But ranking today involves far more than link counting. Backlinko's analysis catalogs over 200 ranking factors, and broader estimates from MarketMymarket.com put the number above 500. Google's own documentation says its algorithms consider "the words of your query, relevance and usability of pages, expertise of sources, and your location and settings." That's a deliberately vague summary of an enormous system.
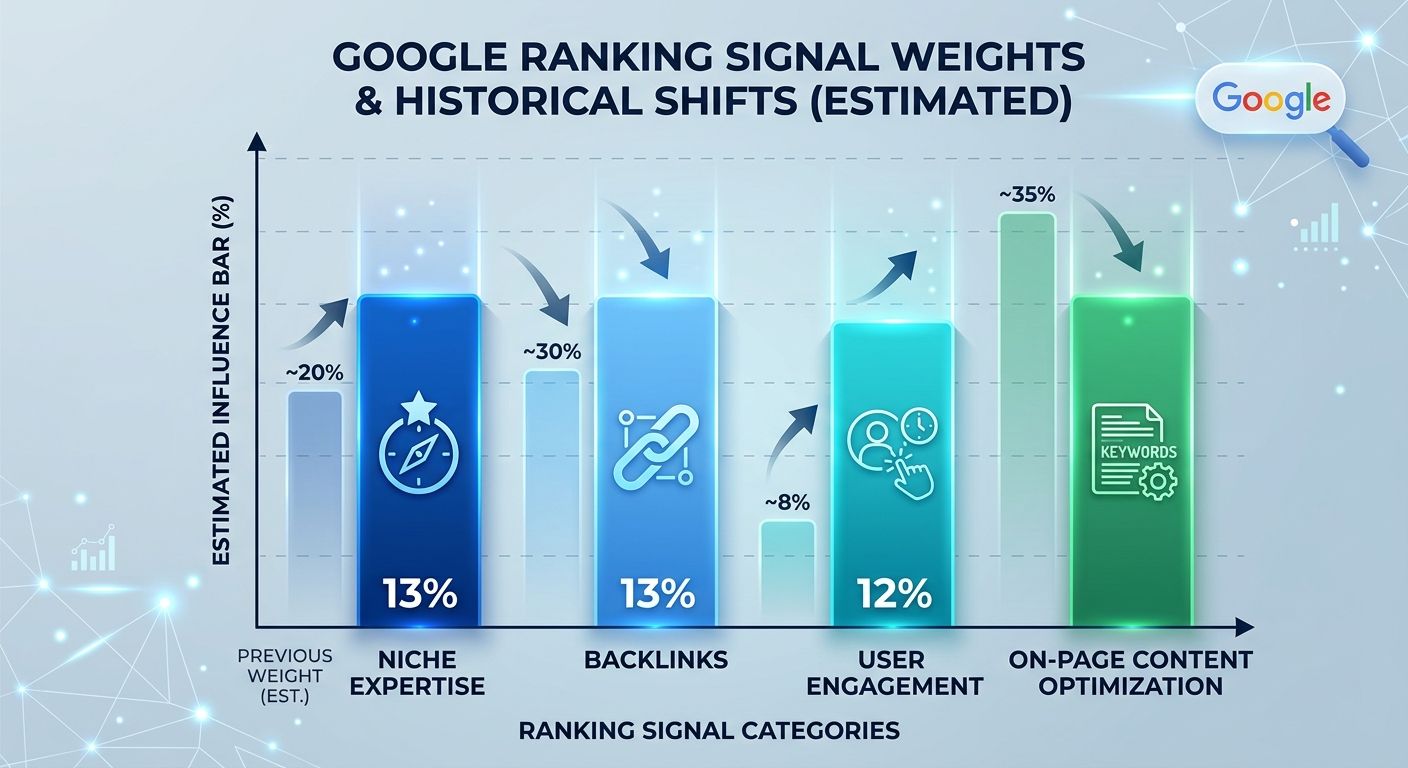
The 2025 ranking factor analysis from First Page Sage puts specific weights on the major signal categories. Niche expertise holds at 13%, underscoring that Google rewards sites with deep coverage of a specific topic. Trustworthiness and on-page content optimization remain significant. Backlinks, the direct descendant of PageRank's link-voting concept, have declined from 15% to 13% of the algorithm's weight. User engagement signals—click-through rate, dwell time, bounce behavior—have grown to about 12%.
That shift is significant. Leaked internal documents revealed a system called NavBoost, which tracks how users interact with search results. If people consistently click on your result and stay on the page, that's a positive signal. If they click and immediately return to the results page, that tells Google something too. The implication is clear: ranking well depends partly on satisfying the people who click through to your page, not only on satisfying the algorithm that put you there.
Google's ranking systems also operate at the page level, not the site level. Their ranking systems guide makes this explicit: individual pages are evaluated using a variety of signals and systems. A mediocre page on an otherwise excellent site can still rank poorly, and a strong page on a small site can still rank well. Understanding this helps explain how organic SEO works in practice—it's always about the individual page serving a specific query.
The December 2025 Core Update and Wikipedia's 435-Point Drop
If you want proof that no site is immune to ranking shifts, consider what happened after Google's December 2025 core update. Wikipedia—arguably the most linked-to, most crawled, most indexed site on the internet—lost 435 points in search visibility. That's a massive drop for a domain most SEO practitioners would consider untouchable.
The update emphasized semantic understanding and user experience signals over raw authority metrics. Wikipedia has authority in spades, but individual Wikipedia articles don't always provide the best user experience for a given query. Some articles are dense, poorly structured for casual readers, or tangential to the searcher's actual intent. Google's systems, increasingly driven by machine learning, picked up on those gaps.
This matters because it illustrates how all three stages of the pipeline interact. Wikipedia has no crawling problems—Googlebot hits it constantly. It has no indexing problems—nearly every Wikipedia page is indexed. The breakdown happened purely at the ranking stage, where Google's algorithms decided that for certain queries, other pages served users better. Crawling and indexing are prerequisites, but ranking is the final arbiter of visibility.
PageRank's Long Shadow Over a Pipeline It No Longer Dominates
PageRank still exists inside Google's systems. It's one signal among hundreds. But the algorithm that once defined how search engines work has been steadily diluted by machine learning systems (RankBrain, BERT, MUM), user behavior tracking (NavBoost), content quality evaluation (E-E-A-T frameworks), and now AI synthesis layers that generate conversational summaries directly in search results.
The three-stage pipeline, though, hasn't changed in its fundamental logic since 1998. A page has to be found. It has to be understood. And it has to be judged worthy of showing to a specific person asking a specific question. What's changed is the sophistication at each stage. Crawling now involves JavaScript rendering and mobile-first indexing. Indexing now involves entity recognition and semantic analysis. Ranking now involves hundreds of interacting signals weighted by machine learning models that Google's own engineers can't fully explain in simple terms.
If you publish a URL today, it enters the same pipeline that Backrub built in a Stanford dorm room. The seed URLs are different. The crawl queue is incomprehensibly larger. The index is organized around meaning rather than keywords. And the ranking function has grown from one elegant algorithm to a system so complex that even Wikipedia can lose visibility overnight. But the sequence—crawl, index, rank—still holds. Every page you've ever found through a search engine arrived there through that same three-step process, and every page you'll publish next will have to survive it too.
OrganicSEO.org Editorial
Editorial team writing about Ethical, white-hat, organic SEO education.
Frequently Asked Questions
- How do search engines find and crawl web pages?
- Search engines use crawlers like Googlebot that start with seed URLs and follow hyperlinks to discover and download pages, building an ever-expanding map of the web. URLs can enter the crawl queue through link discovery, XML sitemaps submitted via Google Search Console, or by allowing Googlebot access through your robots.txt file.
- What is crawl budget and why does it matter?
- Crawl budget is the number of pages Googlebot will fetch from your site in a given period. Server response time is critical—a 100ms improvement in server speed can increase crawling activity by roughly 15%, and slow or error-prone servers cause Googlebot to back off, potentially leaving pages uncrawled and unindexed.
- What happens during the indexing stage of search engines?
- During indexing, search engines process and store crawled content in a searchable format. Modern indexing involves rendering JavaScript, analyzing metadata, evaluating structured data, and understanding semantic relationships—allowing Google to understand not just that a page contains a word, but the context and meaning behind it.
- What are canonical URLs and why should I use them?
- Canonical URLs specify which version of a page should be indexed when multiple URLs serve identical content. You can designate a canonical version using a rel="canonical" tag; if you don't, Google picks one for you, which may not be your preferred version.
- What are the main ranking factors Google uses?
- Google considers over 500 ranking signals including niche expertise (13%), trustworthiness and on-page content (significant), backlinks (13%), user engagement signals like click-through rate and dwell time (12%), and semantic understanding of content. Ranking is evaluated at the page level, not the site level, meaning individual pages are judged on their own merit.
- What is NavBoost and how does it affect search rankings?
- NavBoost is a Google system that tracks how users interact with search results—monitoring click-through rates, how long users stay on pages, and whether they return to results quickly. This user behavior data has grown into an important ranking signal, meaning pages must satisfy both the algorithm and the people who click through to them.
- Why do indexed pages not always appear in search results?
- Being indexed is a necessary but not sufficient condition for ranking. According to Ahrefs data, 96.55% of all indexed pages receive zero organic traffic because ranking depends on hundreds of signals beyond just being discoverable and stored in Google's index.