Session IDs and SEO: Why They Hurt Crawlability and How to Fix Them
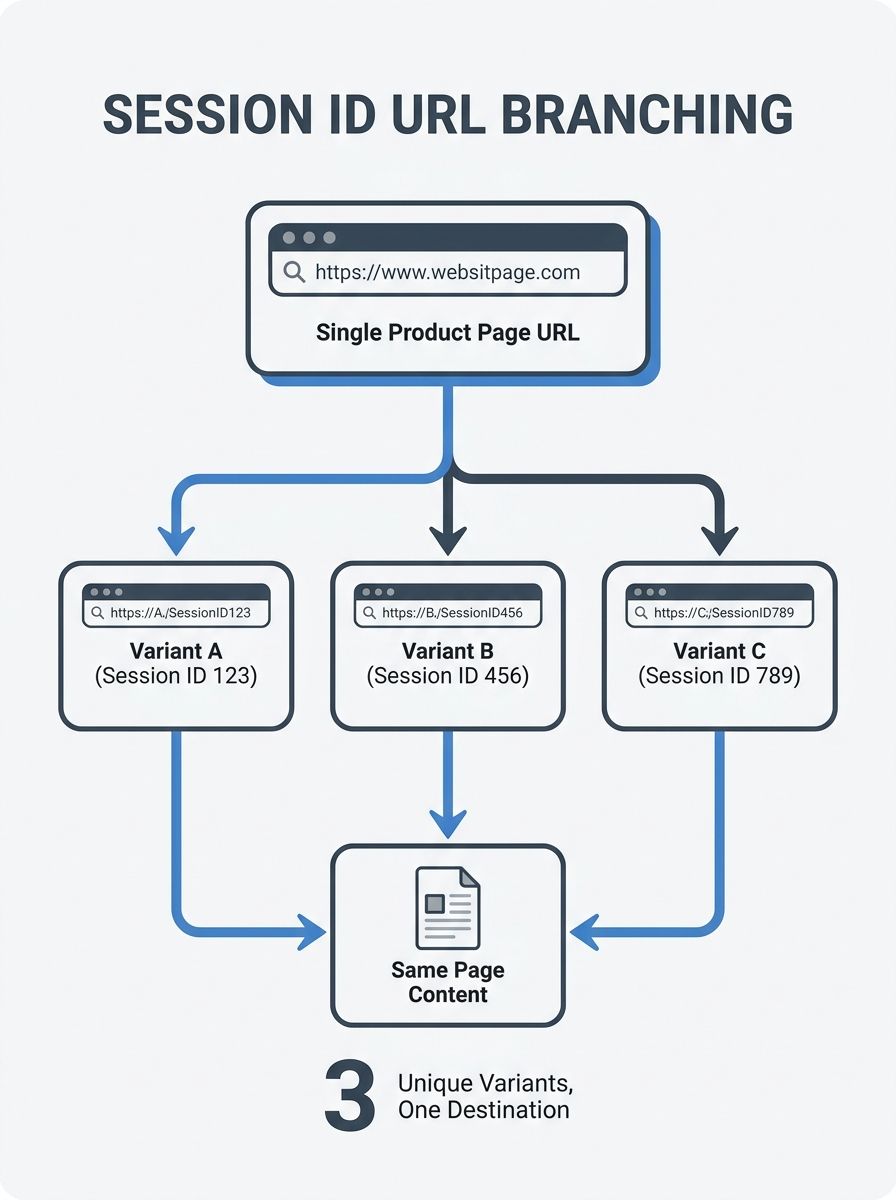
Googlebot doesn't carry cookies between requests. When it hits a page on a site that falls back to URL-based session tracking, the server generates a fresh session ID and appends it to every link on the page. So /products/shoes becomes /products/shoes?
Session IDs and SEO: Why They Hurt Crawlability and How to Fix Them
Googlebot doesn't carry cookies between requests. When it hits a page on a site that falls back to URL-based session tracking, the server generates a fresh session ID and appends it to every link on the page. So /products/shoes becomes /products/shoes?PHPSESSID=abc123, and on the next crawl it becomes /products/shoes?PHPSESSID=def456. Same content, different URL, every single time. If you have 500 product pages and Googlebot visits the site three times a day, the math gets ugly fast: you're presenting thousands of unique-looking URLs that all resolve to the same few hundred pages.
This is one of the oldest technical SEO problems on the web, and it's still showing up in crawl audits with surprising frequency. The relationship between session IDs and SEO is straightforward once you see it, but fixing it requires understanding why your server is generating those URLs in the first place and which cleanup method actually fits your architecture.
How One Parameter Multiplies Into Thousands of Pages
The core issue is that session ID URL parameters turn every page on your site into a near-infinite set of URLs. A session ID is a string of characters your server assigns to each visitor so it can track their browsing state, their cart contents, or their login status. When that identifier gets embedded in the URL as a query parameter, every internal link on the page inherits it. A user clicking from your homepage to a category page to a product page generates a trail of URLs that are unique to that visit and will never be used again.
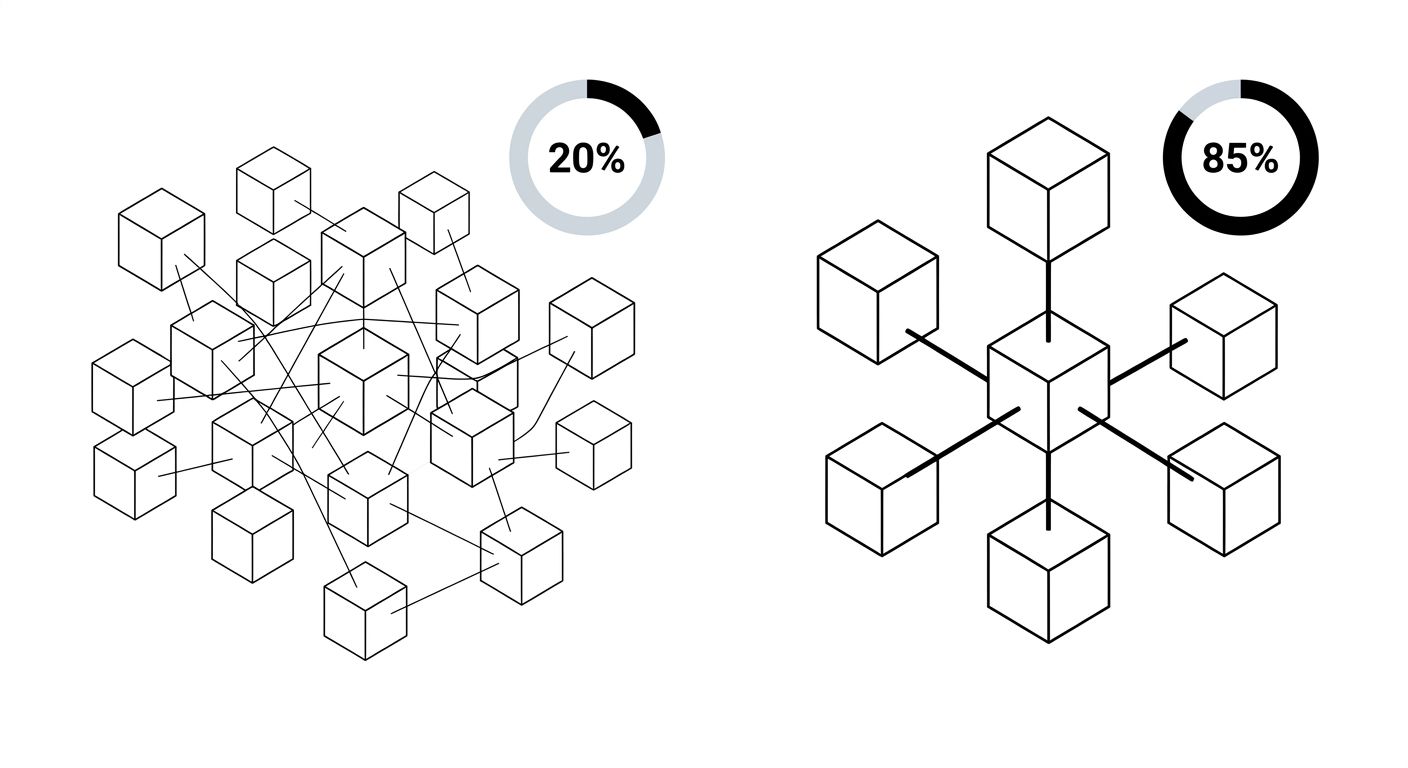
Search engine crawlers treat those URLs as distinct addresses. As Search Engine Land has documented, search engines interpret URLs with session IDs or tracking parameters as individual, separate URLs, which triggers duplicate content problems if nothing intervenes. Your product page doesn't have one URL in Google's index. It might have dozens or hundreds, each containing a different session ID fragment, all serving identical HTML. The duplicate content created by session IDs dilutes the ranking signals that should be consolidating on a single canonical version of each page. Instead of one strong URL accumulating links and engagement metrics, the value gets scattered across a swarm of parameter-laden variations that Google has to evaluate, compare, and attempt to deduplicate on its own.
Understanding how crawling, indexing, and ranking actually work makes this easier to visualize. Google discovers a URL, requests the page, processes the content, and decides whether to index it. When it discovers the same content at fifty different session-parameterized URLs, it has to do that evaluation fifty times before consolidating. That's wasted computation on Google's side and wasted opportunity on yours.
The Crawl Budget Drain
Crawl budget is the number of pages Googlebot will request from your site in a given period. Google allocates this based on a combination of your server's response speed and the perceived value of your content. For small sites with a few hundred pages, crawl budget rarely matters. But for e-commerce sites, large publishers, or any property with thousands of URLs, the math changes significantly. When session ID URLs inflate your apparent site size by an order of magnitude, Googlebot spends its allocation chasing phantom pages instead of discovering new content or recrawling pages that have been updated.
The problem compounds because session IDs are inherently infinite. Unlike a category filter or a sort parameter, which at least has a bounded set of values, session IDs are randomly generated strings. Every crawl creates new ones. Google's own documentation on crawl budget management warns against using noindex to deal with this kind of URL proliferation because the crawler still has to request the page before it sees the directive, which wastes crawling time anyway. The advice is to block pages you don't want crawled at all, not to let Google discover them and then tell it to ignore what it found.
The crawl budget impact of session URLs tends to be invisible until you look at server logs. If you pull your access logs and filter for Googlebot's user agent, you'll often see it requesting URLs with session parameters that a human visitor would never bookmark or share. Those requests are pure waste. Every one of them is a request that could have gone to a new blog post, an updated product listing, or a freshly published landing page. For sites running into indexing delays, session ID crawl waste is one of the first things worth investigating.
Fixing the Root and Cleaning Up the Index
The cleanest solution is to remove session IDs from URLs entirely. Store session data in cookies or server-side sessions. Every modern browser supports cookies, and the edge case where a visitor has disabled them accounts for a negligible fraction of traffic. PHP applications, which are historically the biggest offenders here, can be configured to use cookie-only sessions by setting session.use_only_cookies to 1 in your php.ini file or at the application level. As multiple developers have confirmed on Stack Overflow, accepting cookies to avoid session IDs in URLs and stripping any that remain on subsequent requests is the standard approach. Platform-specific fixes exist too: Magento, CS-Cart, and similar e-commerce systems all have configuration toggles or code-level changes to suppress URL-based session IDs.
But removing session IDs from newly generated URLs only solves half the problem. If Google has already indexed hundreds of session-parameterized URLs, you need to clean up the mess. Canonical tags are the primary tool here. Adding a rel="canonical" tag to every page, pointing to the clean, parameter-free version of the URL, tells Google which version should carry the ranking weight. If your product lives at example.com/shoes/running-shoe, every variation with a session ID should include <link rel="canonical" href="https://example.com/shoes/running-shoe" /> in the <head>. The guidance around canonical tags and session IDs is consistent across the industry: point canonical tags on parameter-laden variants to the primary clean URL, and Google will treat them as a strong signal for consolidation.
For URL parameter handling from the SEO side, robots.txt can block crawler access to session-parameterized URLs entirely. A rule like Disallow: /*?PHPSESSID= prevents Googlebot from crawling any URL containing that parameter. This is more aggressive than canonicalization and appropriate when you're confident those URLs serve no unique content whatsoever. The two approaches work well together: canonical tags handle variants that Google has already discovered, while robots.txt rules prevent new ones from being crawled in the first place. And critically, you need to audit your internal links. Every link within your templates, your navigation, your sitemaps, and your footer should point to clean URLs without session parameters attached. If your CMS is generating internal links with session IDs baked in, no amount of canonical tagging or robots directives will fully compensate, because you're continuously feeding new parameterized URLs to the crawler through your own site structure.
If you're thinking about broader URL cleanup, the principles around structuring SEO-friendly URLs apply directly. Clean, static, parameter-free paths are easier for search engines to parse, easier for humans to read, and far less prone to duplication issues. Treating session ID removal as part of a wider URL hygiene effort tends to produce better results than addressing it in isolation.
Where the Fixes Get Messy
The straightforward advice is to move sessions into cookies and never put identifiers in URLs. But real-world implementations don't always cooperate with clean recommendations. Some legacy platforms still rely on URL-based sessions for specific features like cross-subdomain tracking or affiliate attribution systems that predate modern cookie handling. Ripping out URL-based sessions in those environments means rebuilding the tracking logic, which introduces risk and cost that product teams don't always prioritize.
Canonical tags are described as a "strong hint" by Google, not a directive. This means Google can and does ignore them when it detects conflicting signals. If your canonical points to a clean URL but your sitemap includes the parameterized version, or if external sites have linked to a session-ID URL that got cached somewhere, Google might index the wrong variant anyway. Canonicalization works best as one layer in a multi-layered approach, combined with consistent internal linking, robots.txt rules, and the actual elimination of session parameters from URL generation. Relying on any single fix in isolation leaves gaps.
There's also the question of how much damage has already been done. If Google has been crawling session-parameterized URLs for months or years on a large site, the index may contain thousands of near-duplicate entries. Cleaning that up takes time. Google doesn't process canonical signals instantly, and recrawling all those URLs to discover the new canonical tags happens on Google's schedule, not yours. Understanding what on-page optimization actually involves at the technical layer helps set realistic expectations for recovery timelines. Sites that have addressed session ID duplication typically report gradual improvement over weeks as Google reconsolidates its index, rather than an overnight correction.
The uncomfortable part of this whole topic is that the technical fix is genuinely simple for most modern stacks, and yet the problem persists because it's invisible to anyone who isn't running crawl audits or reading server logs. Session IDs don't break anything a normal user can see. Pages load, products get added to carts, checkouts complete. The damage happens entirely in how search engines perceive and allocate resources to your site, which means it can quietly erode your organic visibility for months before anyone notices the pattern in traffic data.
OrganicSEO.org Editorial
Editorial team writing about Ethical, white-hat, organic SEO education.
Frequently Asked Questions
- What are session IDs and why do they hurt SEO?
- Session IDs are strings assigned by servers to track visitor browsing state, cart contents, or login status. When embedded in URLs as query parameters, they create duplicate URLs with identical content—like /products/shoes?PHPSESSID=abc123 and /products/shoes?PHPSESSID=def456—which dilutes ranking signals and wastes crawl budget as Google evaluates dozens of parameter variations instead of consolidating value on a single canonical URL.
- How do session IDs waste crawl budget?
- Session IDs are randomly generated strings that create infinite URL variations with every crawl. Googlebot wastes its limited crawl budget requesting these phantom pages instead of discovering new content or recrawling updated pages, which is particularly damaging for e-commerce sites and large publishers with thousands of URLs.
- How do I remove session IDs from URLs?
- Store session data in cookies or server-side sessions instead of URL parameters. For PHP applications, set session.use_only_cookies to 1 in your php.ini file. Platform-specific solutions exist for Magento, CS-Cart, and similar systems through configuration toggles or code-level changes.
- Should I use canonical tags to fix session ID duplicates?
- Yes, add rel="canonical" tags pointing to clean, parameter-free URLs on every page variant containing session IDs. This tells Google which version should carry ranking weight, though canonical tags are a strong hint rather than a directive and work best combined with robots.txt rules and clean internal linking.
- Can I use robots.txt to block session ID URLs?
- Yes, robots.txt rules like Disallow: /*?PHPSESSID= prevent Googlebot from crawling session-parameterized URLs entirely. This approach works best alongside canonical tags—canonical handles variants already discovered, while robots.txt prevents new ones from being crawled.
- How long does it take to recover from session ID indexing problems?
- Recovery is typically gradual over weeks as Google reconsolidates its index around canonical tags, rather than an overnight correction. If Google has indexed thousands of session-parameterized URLs for months or years, cleanup takes longer since Google processes canonical signals on its own schedule.
- Why do internal links need to point to clean URLs without session IDs?
- If your CMS generates internal links with session IDs baked in, you continuously feed new parameterized URLs to the crawler through your own site structure. No amount of canonical tagging or robots directives will fully compensate if internal links keep creating session-parameterized variations.
- Why do session ID problems persist if they're easy to fix?
- Session ID duplication is invisible to regular users—pages load normally, carts function, and checkouts complete—so the damage only appears in search engine crawl patterns and traffic data. The issue often goes unnoticed until someone runs a crawl audit or examines server logs.