Keyword Research for Information Architecture: How to Map Search Intent to Site Structure Before Launch
Three methods dominate pre-launch keyword strategy for information architecture: SERP-driven intent mapping, topic cluster modeling, and user-task taxonomy. Each one produces a different site hierarchy, and 96.
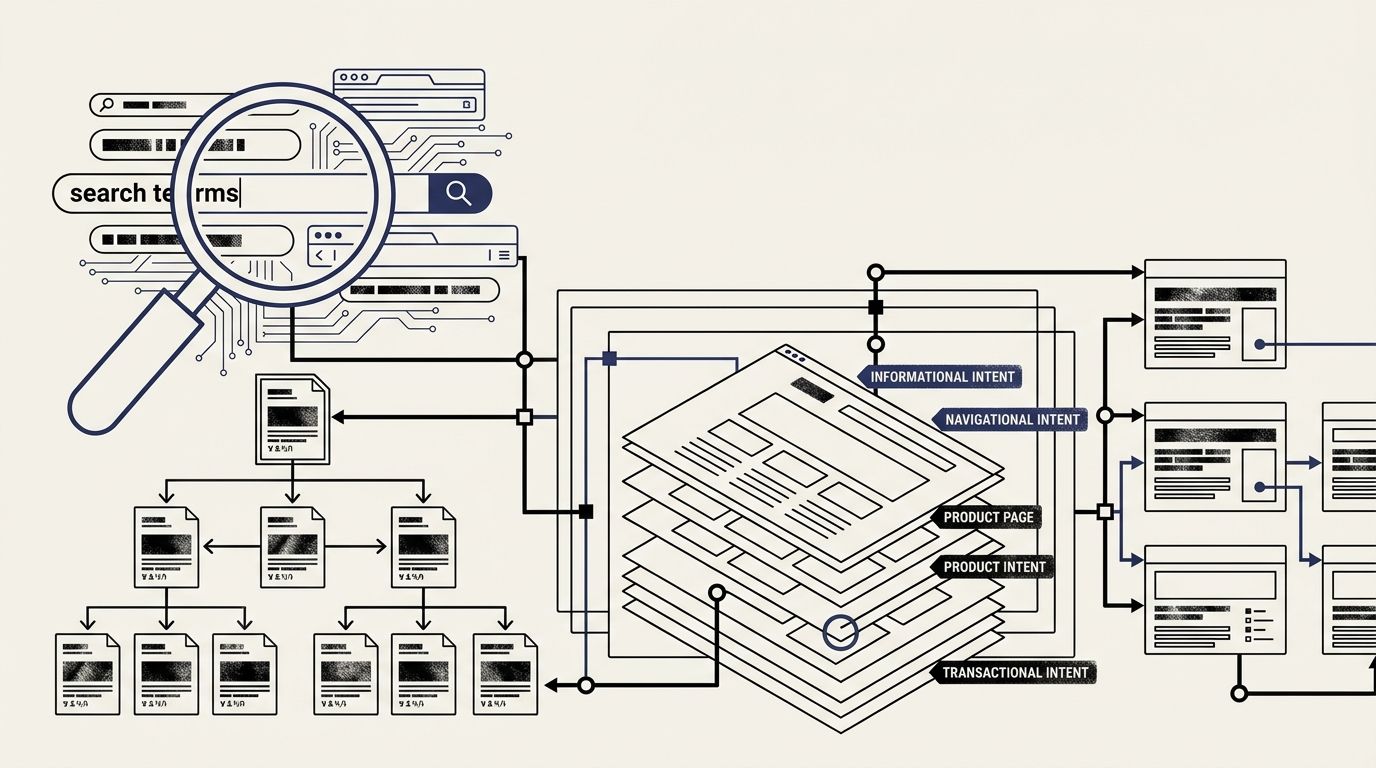
Keyword Research for Information Architecture: How to Map Search Intent to Site Structure Before Launch
Three methods dominate pre-launch keyword strategy for information architecture: SERP-driven intent mapping, topic cluster modeling, and user-task taxonomy. Each one produces a different site hierarchy, and 96.55% of published content that receives zero organic traffic traces back to a mismatch between page format and the searcher's actual task.
The rest of this article walks through each approach, weighs specific tradeoffs, and ends with a verdict on which fits which scenario. If you've already built a search intent map for your full site, you'll recognize pieces of each method. The question is which one should govern your information architecture SEO planning before you write a single page.
SERP-Driven Intent Mapping
This approach treats Google's current search results as the ground truth for what content format, depth, and hierarchy a page needs. You pull your target keyword list, search each term, and catalog what's actually ranking: product pages, long-form guides, comparison tables, video carousels, forums. The SERP tells you what Google has already validated as the right page type for that query.
The process works in three steps. First, export your keyword targets (even a seed list of 50 to 200 terms works for a pre-launch site). Second, categorize each SERP result by page type and the 4 intent buckets outlined in the search intent taxonomy from Insightland: informational, navigational, transactional, and commercial investigation. Third, group keywords that share the same dominant SERP format into single pages or page templates.
As Moz's information architecture guide puts it, the principle is to "go broad to narrow" when translating keyword data into hierarchy. Your broadest, highest-volume terms become category pages. The narrower, more specific terms become individual pages nested underneath.
The strength here is precision. You're building your site's architecture from observed data, not assumptions. When AI Overviews now trigger for 39.4% of informational queries, knowing which of your target terms already have AI Overviews (and what format those overviews pull from) shapes whether you build a full guide page or a focused FAQ section. If you're tracking how AI Overviews affect CTR, this is where that data directly informs IA decisions.
The tradeoff: SERP-driven mapping requires manual analysis of dozens or hundreds of result pages before launch, which is labor-intensive for small teams. It also anchors your architecture to Google's current state, which shifts. A site built entirely from SERP snapshots in May can find its assumptions outdated by October if Google reshuffles featured snippet eligibility or rolls out a new SERP feature.
When SERP Mapping Works Best
Teams with access to a tool like Ahrefs or Semrush (we've compared which tool wins for keyword research) can automate part of the SERP cataloging. Sites launching into competitive verticals where intent signals are well-established benefit most. E-commerce sites with 100+ product SKUs and content-heavy B2B sites with clear buyer journey stages are strong fits.
Topic Clusters Organize Around Pillar Pages
Topic cluster modeling groups your keywords into thematic bundles, then assigns each bundle a pillar page (the broad, authoritative resource) surrounded by cluster pages (the specific, supporting content). Internal links flow from cluster pages back to the pillar, concentrating authority and signaling topical relevance to crawlers.
NAV43's information architecture blueprint documents the core structural rule: build a flat hierarchy where no page sits more than 3 clicks from the homepage. One case study they reference showed a 46% increase in organic traffic and an 18% drop in bounce rate after restructuring from a deep, buried architecture to a logical cluster model. Sites that implement flat, clustered hierarchies generally see organic traffic lifts in the 40% to 75% range, depending on how fragmented the original structure was.
The keyword research process here differs from SERP mapping. Instead of analyzing individual result pages, you're grouping 200 to 2,000 keyword targets by semantic similarity and parent-child relationships. A pillar page on "project management software" might anchor cluster pages on "Gantt chart tools," "agile sprint planning features," and "project management for remote teams." Each cluster page targets a distinct keyword phrase but links back to the pillar.
As a DMNews analysis of keyword-driven IA argues, "keywords function as a distributed, continuously updated architectural blueprint." The search queries audiences generate every day encode the categories and hierarchies your site structure should reflect. You don't need a separate IA workshop to discover these categories if you've done the keyword research first.
The tradeoff: Topic clusters work brilliantly for content-heavy sites (SaaS blogs, media publishers, educational platforms) but impose an artificial hierarchy on sites where content doesn't naturally cluster. A 14-page service site, for instance, doesn't have the volume to justify pillar-cluster architecture. We documented how a small service site recovered traffic through internal link fixes alone, without adopting clusters at all. And cluster models require ongoing maintenance: as your seed keyword framework scales, new cluster pages need to be woven into the existing link architecture or the whole model fragments.
When Clusters Work Best
Sites planning to publish 50+ pages at launch or within the first 6 months. Content marketing programs where ongoing blog output feeds the cluster structure. B2B companies with complex product lines that naturally decompose into subtopics. If you're launching with fewer than 20 pages, the overhead of cluster planning exceeds the payoff.
User-Task Taxonomy Reverses the Direction
Where SERP mapping and topic clusters both start from keyword data and work toward site structure, user-task taxonomy starts from what a visitor wants to accomplish and reverse-engineers the pages needed to support those tasks. You define 5 to 12 core user tasks (buy, compare, learn, troubleshoot, contact, evaluate pricing), then map keyword groups to each task, then build the page hierarchy around task completion paths.
The pre-launch SEO checklist from Skyno Digital describes the discipline this requires: "Create a spreadsheet. List every URL you plan to launch. Next to each URL, assign one primary intent." That single-intent-per-page constraint is the backbone of user-task taxonomy. Every page exists because a specific task demands it, and the URL structure reflects the task hierarchy rather than the keyword hierarchy.
This approach borrows from UX research methodologies (card sorting, task analysis, user journey mapping) and layers keyword data on top. You're answering the question "what does someone need to do here?" before asking "what keywords does this page target?"
The tradeoff: User-task taxonomy produces clean, intuitive navigation that converts well. Responsival's analysis of IA and SEO working together captures the tension: even if you place the right keywords in the right places, messy IA kills conversions. And even if your IA is flawless, optimizing for wrong keywords kills conversions too. Both pieces have to align. The risk with user-task taxonomy is that it can underweight search volume data. A task-driven IA might produce pages that are logically perfect but target terms with negligible search demand, because the task map was built from internal assumptions about users rather than from observed search behavior.
When Task Taxonomy Works Best
Service businesses, SaaS products with defined user workflows, and sites where conversion architecture matters more than content volume. If your site's primary purpose is lead generation or product sign-up rather than content publishing, user-task taxonomy prevents the common mistake of building an information architecture that looks good in a keyword report but confuses the actual human trying to buy something.
How to Choose Between These Three
The site hierarchy keyword mapping method you pick depends on three variables: content volume at launch, team capacity for pre-launch research, and whether the site's primary goal is content discovery or task completion.
Criteria | SERP-Driven Mapping | Topic Clusters | User-Task Taxonomy |
|---|---|---|---|
Best for page count | 20–100 pages | 50+ pages | 5–30 pages |
Pre-launch research time | 15–40 hours | 8–20 hours | 10–25 hours |
Primary strength | Precision on intent-to-format matching | Scalable content architecture | High-conversion navigation |
Primary weakness | Labor-intensive, snapshot-dependent | Requires ongoing link maintenance | Can underweight search volume |
Ideal site type | E-commerce, competitive B2B | Content publishers, SaaS blogs | Service sites, SaaS products |
Handles mixed intent well | Yes (per-SERP analysis) | Moderately (pillar absorbs) | No (single intent per page) |
For most sites launching with 30 to 80 pages of mixed content types (some transactional, some informational, some commercial), a hybrid of SERP-driven mapping and topic clusters produces the strongest pre-launch architecture. Use SERP analysis to determine page formats and intent assignments, then organize those pages into clusters for internal linking and hierarchy. Layer user-task thinking into your navigation design so that the menu structure reflects what visitors want to do, even if the underlying page hierarchy follows cluster logic.
Sites launching lean (under 20 pages) should default to user-task taxonomy. You don't have enough content to justify cluster architecture, and SERP analysis for 15 keywords takes an afternoon, not a methodology.
Sites launching heavy (100+ pages) need SERP-driven mapping as the foundation, because without per-keyword intent validation at that scale, you'll ship pages that target the wrong format and join the 96.55% that get zero traffic. Build clusters on top of that SERP-validated foundation.
The information architecture you ship on day one will determine your crawlability and authority flow for months before Google fully processes any structural changes. Getting the keyword research site structure alignment right pre-launch is cheaper and faster than rebuilding after the index has formed its opinion. Pick the method that matches your constraints, do the research before you touch a CMS, and launch with a hierarchy that Google can read as clearly as your visitors can navigate.
OrganicSEO.org Editorial
Editorial team writing about Ethical, white-hat, organic SEO education.
Related Articles
Keyword Research as Site Architecture Reverse-Engineering: How to Extract IA Decisions from Search Data
ClickRank's intent mapping documentation shows that sites assigning exactly one intent type per URL eliminate page-level content overlap entirely, because each URL resolves a distinct query class.
The Seed Keyword Expansion Playbook: Moving Beyond Single Terms to Semantic Clusters Without Tool Dependency
Google's algorithmic evolution from Hummingbird through BERT and MUM turned single-keyword targeting into a losing strategy.
From Seed Keyword to Search Intent: Building a Keyword Research Framework That Scales Beyond Tool Suggestions
Every keyword tool on the market outputs the same four columns: search volume, keyword difficulty (a score from 0 to 100), CPC, and a one-word intent label.